Human-Empowered Artificial Intelligence: AI 3.0
Building the collective mind of humans and machines is the future of AI

The three waves of AI and where we are headed
The quest to capture human thought, reasoning and knowledge in a machine has deep roots, dating back to the late1600s with Gottfried Leibniz’s “knowledge calculator”. The advent of digital computers fueled a leap forward in the latter half of the 1900s, as the first wave of AI showcased systems that mimicked human expertise through a set of hand-programmed heuristics.[1]
The second wave of AI followed soon after, developing the first wave’s expert systems into statistical learning models and neural networks that have changed nearly every area of our daily lives.
This paper makes the case that the third wave of AI will be human-empowered, a blend of human and machine that will outperform either one on its own.
Human-empowered AI augments human judgment, experience, and intuition with the systematic power and discipline of learning from data, opening new frontiers for optimizing human machine collaboration. Evidence for measuring a collective IQ was first published in 2010 and brought into sharper view in Tom Malone’s recent book “Superminds”. [2,3] Scaling the collective IQ through AI holds huge promise for near term impact on problems that require generalized intelligence. The integration of human and artificial intelligence will power a third wave of AI applications.
Before proceeding into the body of this story allow me to provide a summary of the points to be made:
AI 1.0: Handcrafted embedding of human expertise in software led to lasting results that were not broadly deployed as continuously learning AI systems due to the cost of maintaining the hand-crafted models. The explanatory capabilities of symbolic AI systems increased the ability for experts to understand how their logic was embedded in a program, dramatically increasing transparency and speed of embedding expertise in software. This enabled the first wave of AI to broadly expand the types of applications which could be automated.
AI 2.0: Even through machine learning and neural nets existed early on, growth of available data in the late 90s led to models that learn from data. Statistical learning is driving a wave of automation of intelligence that will have massive impact but they too have challenges in the narrowness of application. The cost of maintenance in programming expertise shifted to the cost of building and maintaining training data sets. Lack of explanatory capabilities limit trust in models. Unsupervised learning and learning from sparse data remain challenging.
AI 3.0: The third wave of AI will be human empowered, combining the best of the first two waves of AI bringing together human reasoning and judgement with statistical learning. The science of collective intelligence is showing early signs of catalyzing automated creation of models of collective intelligence, automating the process of knowledge acquisition and maintenance. Furthermore, these models support explanation, creating higher levels of trust between humans and AI systems.
I will provide a personal perspective in this story because it is a journey of discovery and perhaps that journey will provide context to you the reader.
My interest in AI began in the mid 60s, a decade after the first conference at Dartmouth in 1955 launching the science of artificial intelligence. This interest influenced my academic studies and led to publishing work on applying machine learning to problems in applied physics and later to papers on natural language processing and knowledge representation. In 1980, as the first commercial wave of AI was beginning, I headed up the knowledge systems team at Texas Instruments, one of the emerging corporate AI labs. TI had a strong AI team largely from MIT and was the first corporation to commission Lisp Machines from Lisp Machines Incorporated. The two first commercial Lisp Machines (other than those at Xerox’s Palo Alto Research Center) were built on the floor outside my office at TI by Richard Greenblatt. At TI we explored applications of AI to VLSI design, oil exploration, intelligent tutoring, and natural language processing.[5] One early application we built on the Lisp Machines was a hyperlinked browser for navigating text in a network of computers.[6] While using knowledge graphs to model text is not AI per se, it demonstrates how the pursuit of AI led to novel applications expanding the boundaries of computation. I mention the personal aspect because hands-on coding and development of these systems fuels the points made in this article.
Handcrafted Computational Knowledge Models: AI 1.0
The core technologies of the first wave of commercial AI were symbolic knowledge representation and reasoning (largely based on the symbolic programming language Lisp). DARPA characterizes this era as “Hand Crafted Knowledge,” AI 1.0. There were many success stories from this era of systems built on computational models of human knowledge and expertise. Applications in manufacturing automation, configuring complex systems, diagnostic systems, simulation of complex processes, inventory based pricing for airlines, fraud detection, and a multitude of other examples were presented, demonstrated and sold at ever growing trade shows and scientific conferences on AI. For example, IntelliCorp worked with Republic Airlines to develop the “Seat Advisor” a first example of inventory-based pricing in the airline industry. It was not unusual for these early prototypes based in AI technology to later scale to new disruptive applications. There are many examples in manufacturing, configuration management, and airline inventory-based pricing that started as Expert Systems that later were coded in a traditional software language. The first commercial wave of AI was driven by the desire of corporate leadership to capture the knowledge of its most valuable experts into a corporate asset in the form of a knowledge-based system.
While at TI, I worked on a design for a framework for building knowledge-based systems seeking to find a way to embed human expertise in software. In 1982, I was recruited by Prof. Ed Feigenbaum, one of the key leaders of the Expert System era, to join IntelliGenetics. There we launched the Knowledge Engineering Environment (KEE) at IJCAI 83 in Karlsruhe Germany.[7] The KEE development platform embodied components that defined the first commercial wave of AI: Object Oriented Programming, Graphical User Interfaces, Frame-based knowledge representation, rule-based reasoning, knowledge-based discrete event simulation, and knowledge-based queries to databases.[8] Within 18 months after launch there were over 100 systems deployed into many of the top R&D centers of global leading corporations. IBM certified KEE as a “program product” within its product family. By the mid 80s the market for AI was projected to be $2 billion by 1990. IntelliGenetics (INAI) went public as the first AI company in 1983 (INAI later changed its name to IntelliCorp) and had a second public offering in 1985. In just a few years after conceiving the idea of an integrated frame-based reasoning system, I was astounded to see the impact. As a co-developer of KEE, it was an amazing experience to witness a team of brilliant engineers from leading universities and research labs come together in just months and launch a new way to embed human expertise in software. KEE was not open source but it was a platform that encouraged collaborative development.
While the first wave of AI inspired graphically rich interfaces, expert systems, diagnostic systems and more, the AI winter set in and the perception was that symbolic AI failed. Three things forced AI 1.0 into remission:
- the cost and effort of knowledge acquisition (hand crated knowledge model maintenance was too hard),
- limitations of hardware performance (the KEE system that managed configuration management for Navistar ran on a very large mainframe), and
- the limited availability of AI trained talent.
The AI winter marked a massive reduction in commercial applications of AI. However, work in symbolic AI went on in some industrial labs and research centers. Concepts like the semantic web were developed and deployed. In the late 80s and early 90s work in neural networks grew with a firm footing in fraud detection.
Foundational developments in AI 1.0 played an enduring role in the development of AI platforms. These include:
1. Representation, reasoning, and work in ontologies produced enduring facilities with knowledge graphs, the Semantic Web, web browsing, web search and a variety of methods for dealing with managing unstructured data such as free text.
2. Natural language processing and speech recognition technologies have roots back into the 60s with Markov models and statistical methods used by IBM researchers in the 70s. [9]
3. Bayesian Networks introduced by Judea Pearl in 1985 and further developed in his book are foundational to mainstream developments in AI 2.0.[10]
4. Artificial Neural Networks: Work that began in the 60s and continued through the 70s, 80s and 90s, came to full life in the early 21st century fueled by the availability of data for training and computing power.
AI 2.0: Learning from data
The second wave of AI (AI 2.0) began to take off as the mass of data from internet commercialization grew. Learning relationships from data found home in artificial neural network (ANN) models. The need to hand craft knowledge was replaced by techniques to train and build mathematical models from data. Whether one used ANN models or not, the bottom line was to learn the mathematical model that best mapped input data to desired outputs by training by minimizing the errors.
This second wave of AI has solid historic roots in mathematical techniques from statistical mechanics and thermodynamics. To that point, Geoffrey Hinton, developed models such as the Boltzmann Machine which has its roots in statistical mechanics. The latest model for how the brain works based on the “Free Energy Principle” is a strong case in point. In addition, the reason deep learning works is because of its connections to renormalization groups in physics.[11] The interaction between models in physics and models in statistical learning from data continue to grow with the growth of AI 2.0.
Learning from data, dominated AI 2.0 for the past decade and the results are astounding. We can in fact develop mathematical models that outperform humans: in playing games (Chess, Go, Jeopardy), in translating from one language to another, and in a vast number of applications where AI 2.0 has mastered automation in previously untouched application categories. There is substantial evidence that the second wave of AI will continue to gain momentum in automating many tasks previously believed to require human intelligence. However, it will have a defined boundary of applicability.
Applications that learn from data will have ever increasing impact on all aspects of business and daily life. However, there are clear signs that signal limitations. Using sophisticated statistical learning from data can lead to high accuracy in somewhat narrow domains. It falls short when it comes to trust and explainability. When a system gets it wrong, particularly in cases obvious to a human, we stop trusting. Examples abound in speech understanding, spelling correction, and object recognition. Use a system out of context and it fails miserably. An example here is use of a navigational system in areas where the mapping data is sparse. Systems do not maintain a model of the context of their best performance. One consequence of narrow model applicability (e.g. the model works best in zones of adequate training data), is cost of maintenance. The cost of hand crafting code to represent expertise has been replaced by cost to develop and maintain trained data models.
Transition in AI technologies
There is evidence that we are reaching a point of transition in AI technologies. There are applications that point to this need:
1. Applications requiring interaction and trust between human and machine such as financial investments or medical decision making where human judgement is augmented by AI but not replaced. Trust requires integrating machine models with human cognitive models. Trust requires AI systems to explain how they solved a problem.
2. Applications leaning into the need for generalized AI such as future predictions from scarce data. This includes applications such as financial investments for information poor entities (startups, future drugs, new discoveries from science etc). This leads to another aspect of generalized AI, understanding when and where to apply different analysis or problem-solving strategies leading the the third point.
3. Applications that require contextual assessment of multiple models. The vast majority of AI 2.0 models have a context of best performance. Understanding and judging context of applicability of models requires integration with human judgment and cognition.
In the first case, explanatory methods are needed. In AI 1.0 explanation was fundamental to the hand crafting process of building knowledge models thus explanation was core to the methodology. In AI 1.0 explanation was used by the knowledge engineer to debug the computational model generated from knowledge acquired through an interview process. Substantial work developing ontologies and semantic frameworks further supported the ability to generate explanations that integrated well with human cognitive models.
While significant work is going on attempting to instrument neural network models for explanation, there is a fundamental limit to how deep such efforts can go. One possible extension is to develop frame works that wrap so called blackbox models in a kind of skeletal ontology which build explanations. This is close to some approaches that are evolving today in the development of explanatory systems. For example, work at MIT by Joshua Tenenbaum on re-engineering common sense and developing a Neural-Symbolic Concept Learner are directionally aimed at bridging the gap between connectionist and symbolic models.[12,13] The workings of a blackbox model may be opaque, but a skeletal ontology provides an over-riding transparency of supporting explanation.
The second case leans more heavily on generalized intelligence: the ability to imagine outcomes from very little data. Generalized AI will be available 10 years from now for many decades into the future. This was in fact researched and is highlighted in Superminds by Tom Malone:
When researchers Stuart Armstrong and Kaj Sotala analyzed 95 predictions made between 1950 and 2012 about when general AI would be achieved, they found a strong tendency for both experts and nonexperts to predict that it would be achieved between 15 and 25 years in the future — regardless of when the predictions were made.3 In other words, general AI has seemed about 20 years away for the last 60 years.[14]
As mentioned earlier, we all experience the limitations of current AI models on a daily basis in the form of failure of speech recognition systems, failure of navigation systems, failure of spelling correction programs … a list that will grow with the AI systems that touch our daily lives. Today’s systems do not have an understanding of their context of best performance or know when to switch to a different model or approach to solve a problem.
Simply put, there is too much reliance on data-only approaches. We need to reconnect with earlier work on knowledge representation and reasoning.
The new wave
Clearly AI 1.0 and hand crafting human knowledge bogged down under the weight of knowledge acquisition. The mission of collective intelligence as defined by MIT’s center for collective intelligence embodies a vision for a new wave in AI development: AI 3.0 The MIT Center for Collective Intelligence explores how people and computers can be connected so that — collectively — they act more intelligently than any person, group, or computer has ever done before. We have not even begun to scratch the surface of truly understanding how the human brain learns thus projects like MIT IQ and Stanford’s Human-Centered Artificial Intelligence (HAI) were launched in recent years. I attended the initial conference for MIT IQ. It is more accurate to state that generalized AI is at the beginning of a long quest integrating research from all fields, neuroscience to physics. During the conference, I did not encounter the notion that we are close to a generalized AI that will outperform humans. Rather the following statement resonated:
“Imagine if the next breakthrough in artificial intelligence came from the root of intelligence itself: the human brain.”
The broad research initiatives at MIT, Stanford, UC Berkeley (and I am certain many other institutions) treat the science of artificial intelligence as highly linked to an extensive range of scientific research initiatives. As part of this grand program it seems clear that instrumenting and automating how humans use knowledge to solve problems and make predictions must play a critical role. For that reason, AI 3.0 will benefit substantially from incorporating human-empowered AI and collective intelligence.
The mission of human-empowered AI is to use AI technologies to automate the process of building computational models of collective knowledge: collective knowledge acquisition.
These models are built leveraging work in collective intelligence, deep NLP, and learning technologies that learn from group interactions. The resultant collective knowledge models may then be used to test and train with ground truth data. Human-empowered AI empowers the three application areas mentioned above by:
1. Building trust through explanation and integration with human cognitive processes.
2. Leveraging collective human skills of imagination and judgement (skills under the long tail of generalized AI development).
3. Providing a framework for contextual adaptation (DARPA’s third wave definition states: System that construct contextual explanatory models for classes of real world phenomena.)
Before going into a specific example, here are a few key tenets of human empowered AI.
Human-empowered AI:
- is founded on collective knowledge models based on the tenets of collective intelligence. A powerful benefit of collective intelligence is that the cognitive diversity of participants increases prediction and decision accuracy. The first wave of AI depended on manual knowledge engineering typically with one or a small set of experts. Building on the results of collective intelligence increases the quality on predictive value of the resultant knowledge model.
- automates the process of collective knowledge model acquisition and creation. The first wave of AI was hand crafted. Human-empowered AI uses AI technology to acquire and build a collective knowledge model. The resultant collective knowledge model is stored in a computational form (specifically a Bayesian Belief Network in our case).
- is interoperable with AI 2.0 (black box) models and as such delivers explanations of inferred results.
A case example: startup investing
In order to get a better understanding of a specific example of human empowered AI, I provide a brief overview of the results of a multi-year effort in the specific application case of creating a human empowered AI system for predicting success of startup investments.
Whenever capital is deployed, one or more individuals make a judgement call to invest or pass. In most investment scenarios there is an investment committee that makes the call to deploy capital. Our project focused on seed and series A investments where there is little to no reliable predictive data and the process is highly reliant on human judgement.
The project was initiated as part of a new company, CrowdSmart, founded in 2015 to create a technology platform that would change the way capital is deployed to startups. (My co-founders were Kim Polese, Markus Guehrs and Fred Campbell). We believed that a scalable, trusted investment rating (like a Moody’s rating or a FICO score), and guidance would level the playing field to create more equitable opportunities for startups and better outcomes for investors. The results below stemmed from work done by the CrowdSmart team over the past 5 years.
The process we used to build predictive knowledge models of startups follows:
— First, we build an assessment and evaluation team (investment committee if you will) for each startup using the principles of collective intelligence to insure cognitive diversity of the team (more on why we use collective intelligence in subsequent paragraphs). Each team member has access to an extensive data room with the typical materials any VC would use for an investment decision.
— Second, the evaluation team is guided through a multi-day asynchronous process of interaction and scoring. The process starts with a live Q&A discussion with the founding team. This session is recorded and transcribed. The team is then invited to review and provide their assessment and feedback along four discussion areas: the overall business (e.g. market, product market fit, competition), the team, the network value of early advisors and investors, and a discussion of “conviction” e.g. would you yourself invest or recommend to a friend or colleague. Each area is scored on a 1 to 10 scale. The evaluators are encouraged to provide free form text descriptions of the reasons for their score. Once the process begins, the identity of the investor is not visible to the startup team so their scores and comments are private to the investor.
— Third, the system creates effectively an “idea competition” where ideas of peers are sampled and rated in priority order in order to learn shared priorities and relevance on why the startup under consideration will be a successful investment or not. The process is single blind thus the competition is based on the quality of the idea not who generated it. Data striped of identities is made available to the startup team and the investors encouraging discussion and resolution of questions. The system records each transaction and allows connecting review of evidence (as represented in the discussion) to changes in belief about the success trajectory of the startup.
The figure below summarizes the process:
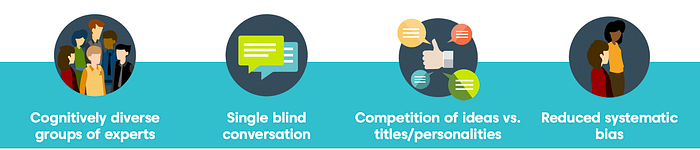
Knowledge acquisition from a diverse group results in reduced bias.
Research in collective intelligence states that a cognitively diverse group of well-informed individuals will out-perform any individual expert in predictive accuracy. This is captured in the Diversity Prediction Theorem which states that the diversity of a group reduces the group error in making a prediction.[15]

Given that we have properly balanced the group for diversity based on collective intelligence principles (done algorithmically), the challenge remains as to how best to extract a knowledge model from their inputs and interactions.
We learn from a group of evaluators a statistically valid representation of their collective view by moderating and measuring the results of their discussion. To do this we use a method that is a close cousin to how search works.
1. Ask an open-ended question with a focus (What must this management team do to be successful at executing their strategy?)
2. Allow for free form submission of their thoughts (before seeing the opinions of others)
3. Sample the universe of opinions submitted by all evaluators and provide the sample list to the reviewer to prioritize based on relevancy to their views.
Submitted priorities in step 3 result in a scoring event that then informs the sampling algorithm. This process is modeled as a Markov process that converges to a stable representation of the collective shared view. This process has been shown to produce a statistically valid rank ordering of shared opinion, turning bottom up qualitative free form statements into a rank ordered list based on shared relevancy. The figures below are from a simulation of the sampling and scoring process.
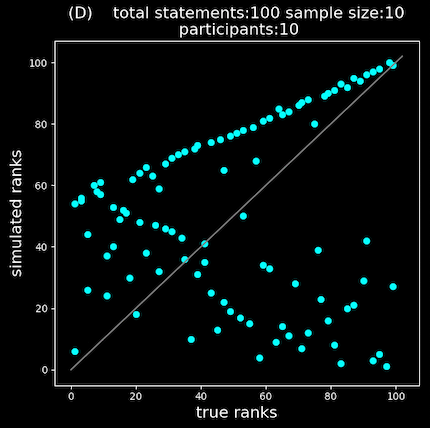
The diagram shows “true rank” vs the “simulated rank” or learned ranking. The system starts out with statements having no shared relevance (e.g. random).
Based on scoring patterns over time the system learns the true rankings:

We can learn from a group the statements or propositions that reflect the opinion of the group with statistical accuracy.
This process has been deployed in predicting consumer preferences from collective conversations in media and consumer packaged goods. The process was tested in parallel studies and certified as convergent and reproducible.
This process is core to collective knowledge acquisition. From it we can then use natural language processing techniques to learn the topics or themes that are driving a prediction or decision. For those of you familiar with Markov processes and related algorithms such as PageRank this should seem reasonable. Once you have established a basic means to recognize prioritizing interactions, the ability to model it as a Markov process becomes clear.
From this framework we can now build a knowledge model. Each quantitative score (e.g. Team Score) has an associated set of statements describing the reasons for the score. Independently these statements or reasons are ranked by the collective group of evaluators independent. Since evaluators do not know the associated quantitative score associated with a particular statement each ranked statement will have associated with it a distribution of scores.
Specifically:
1. Each statement made by any evaluator is scored by peers as to whether or not it is relevant to the discussion
2. Each quantitative score has a collection of statements ranked by their relevancy to the peer group.
3. Themes or topics learned through NLP have a quantitative distribution derived from the associated scores with statements.
Given that the evaluation process can extend to a couple of weeks, there is an opportunity to get a rich amount of data on any individual investment opportunity yielding typically hundreds of quantitative data points and tens of thousands of words.
We now have the basis for constructing a knowledge model in the form of a Bayesian Belief Network (BBN). Statements and topics are linked through conditional probability tables. For example, a specific expert (Expert 38) made a comment as a reason for their score. That comment was classified into a theme or topic by an NLP theme classifier. The theme consists of a collections of comments each comment having a relevancy score. Therefore, the theme has a relevancy distribution, it also contains a distribution of quantitative scores. From this we can infer that certain comments imply certain scoring patters which infer the overall assessment of the probability of success.
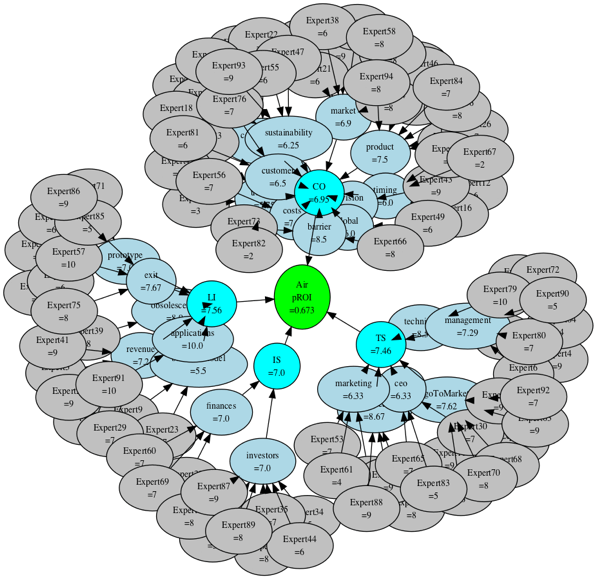
The BBN model for each startup is produced by the system during the course of an evaluation of a startup described above. The model is an executable knowledge model that yields estimates of probability of being a successful company. Specifically, the probability, pROI, in the center of the figure is an estimate of the likelihood of the company establishing funding momentum (e.g. getting to series A/B). The score in conjunction with the BBN provide an explanation for the score. The initial feature set used to frame the evaluation process were derived from research on best practices in early stage investing. Thus the Bayesian prior (the beliefs about what constitutes a great startup investment) is based on a feature set derived from the heuristic: Startups with a strong market opportunity, a strong team, a set of early advisor/investors with strong network connections, and with a highly convinced set of investors are most likely to succeed. The process of building the BBN models the investor market view of that proposition as represented by the evaluation team in the context of a specific startup. Thus, the BBN is a collective knowledge model that predicts the startups ability to gain traction with investors — e.g. is there an investor market for this startup.
In traditional investing an investment committee executes a process of collecting information, deliberating and making a decision. The evaluation process we described in the previous paragraphs is an automated form of an investment committee. The resulting BBN of a particular investment is a persistent knowledge model of the collective human knowledge driving an invest or pass decision. For our project we constructed nearly 100 BBN models. These models provide a memory or audit trail for an investment portfolio empowering a learning platform for improving investment accuracy.
In addition to the BBN, a parallel and interoperable model was employed to learn the weighting of various parameters by applying a measure against “ground truth”. The approach we used for the course of this project was that of conversion to a growth round of funding (ground truth that there actually is an investor market for this startup). This one variable of sustainable funding has the highest correlation with profitable return on investment. Each startup is scored and then tracked over subsequent months and years to determine if in fact high scores predict high probability of follow on funding. In this specific case, we used a logistic regression classifier for the machine learning model.
While we continue work on building accuracy into the model, early results are very promising. The model performs at >80% accuracy meaning that if a startup was scored above 72% (the probability of being in the “invest” class), there is more than an 80% likelihood that the startup will go on to a follow-on round. This compares to roughly 10 % for the general population, ~20% for professional VCs and ~35% for top tier VCs.
There is then substantial promise that interoperable models based on human empowered AI have very high potential in linking areas leveraging collective intelligence predictions (predictions from the a cognitively diverse set of well-informed humans) to real world performance. Furthermore, the results representing predictions and decisions in this form promises to lay a foundation for an entirely new field of applications linking the strongest potential of human intelligence (e.g. imagination, heuristic judgements, learning from small data sets) to the strongest potential of AI 2.0 models (learning from data).
The integration of human cognitive processes with the systematic precision of data-driven learning has massive implications. In order to get the greatest potential from the developments in AI, the link between humans and machines must be transparent and interoperable.
Building the collective mind of humans and machines is the future of AI.
References
[1] Nils Nilson, The Quest for Artificial Intelligence 2010
[2] Woolley, A. W., Chabris, C. F., Pentland, A., Hashmi, N., Malone, T. W. Evidence for a collective intelligence factor in the performance of human groups, Science, 29 October 2010, 330 (6004), 686–688; Published online 30 September 2010 [DOI: 10.1126/science.1193147]
[3] Malone, T. Superminds Little Brown and Company 2019
[4] Kehler, T., Coren, R. Susceptibility and Ripple Studies in Cylindrical Films J. Appl. Phys. 41 pp. 1346–1347, March 1970.
[5] Fisher, William M., Hendler, James A, Kehler, Thomas P., Michaelis, Paul Roller, Miller, James R., Phillips, Brian, Ross, Kenneth M., Steele, Shirley, Tennant, Harry Ralph, Thompson, Craig Warren, “Research at Texas Instrument” SIGART #79, January 1982.
[6] Thomas Kehler, Michael Barnes, Interfacing to text using Helpme, CHI ’81: Proceedings of the Joint Conference on Easier and More Productive Use of Computer Systems. (Part — II): Human Interface and the User Interface — Volume 1981May 1981 Pages 116–124https://doi.org/10.1145/800276.810973
[7] Kehler, T., and Clemenson, G. 1984. KEE the knowledge engineering environment for industry. Systems And Software 3( 1):212–224.
[8] Kehler, T. and FIkes, R. 1985. The role of frame-based representation in reasoning. Commun. ACM 28(9): 904–920
[9] Baum, L. E. An inequality and associated maximization technique in statistical estimation for probabilistic functions of Markov processes. 1972
[10] Pearl, J. Probabilistic Reasoning in Intelligent Systems. Morgan Kaufman 1988
[11] Lin, H.W., Tegmark, M. & Rolnick, D. Why Does Deep and Cheap Learning Work So Well?. J Stat Phys 168, 1223–1247 (2017) doi:10.1007/s10955–017–1836–5
[12]https://science.mit.edu/reverse-engineering-common-sense-in-the-human-mind-and-brain/
[13]Mao, J.,Gan, C., Kohli, P.,Tenenbaum, J.,Wu,J. The Neuro-Symbolic Concept Learner: interpreting the scenes, words, and sentences from natural supervision. ICLR 2019
[14] Malone, T. Superminds, p. 65
[15] Page, Scott E. The Difference. Princeton University Press 2007
